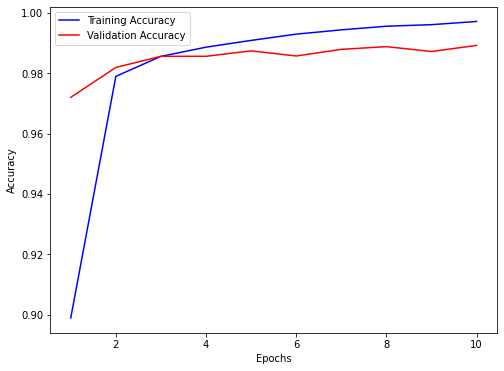
Neural network is simply a pattern finding machine which takes in data and churns out the best corresponding mapping it can learn depending on it's size and epochs! It simply learns to make this mapping as close for training data as possible, the key here is training data! Network does not promise to learn the best mapping for testing data. This is the reason we use validation data to tweak hyperparameters and number of training epochs, so that we don't just overfit on the training data and maybe learn a generalized mapping that could perform as well on testing data. Now, what if we provide neural network with randomly labelled data, will it learn it with as good accuracy as it would have learnt on properly labelled data? Or will it perform poorly?
Before we go ahead, you can find the notebook link here. We will be using MNIST data and train a neural network to recognize the digits looking at these 28x28 images. Keras does support querying this dataset using a very simple call.
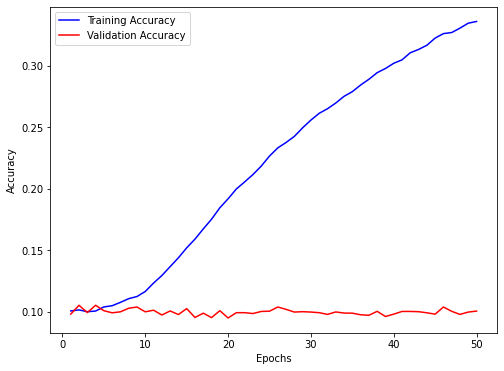
Training on randomly labelled data Next we try training the model with totally random data and the same model as defined above. For each image in our dataset, we randomly assign it a number! We are able to achieve slightly more than 30% accuracy after 50 iterations, which is very poor! We also see that model is deviating from validation data, this can be explained by the fact that the distribution of training and validation data is different! Maybe the network isn't big enough to be able to learn the patterns in this randomly labelled data!
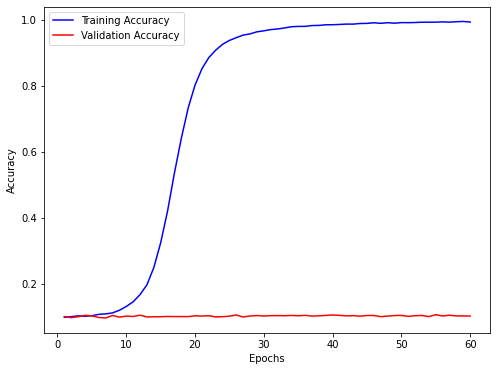
Training a BIGGER network on randomly labelled data So we create a bigger neural network! Note that our expectations at this point are to get 99+% accuracy on the training data. Network will perform very poorly on the validation and testing dataset anyways, because the patterns learnt on randomly labelled training dataset are not valid for validation and testing dataset at all! In essence, we expect network to memoize the training data mapping
Well well well...We do see 99+% accuracy on the neural network for randomly labelled data! However given the lack of structure in the data, it takes longer time to find a mapping which essentially seems to be a learning the training data. Network takes about 50 iterations to finally achieve 99+% accuracy on training data. Note that, as expected, validation data accuracy is pretty low! If you ponder a bit, 10% accuracy on validation data is exactly what one would get if it were to choose same digit every single time, this seems to be in line with fact that data was created at random, assigning one of the 10 digits, with each digit's probability being 0.1.
What do we learn? Neural networks are all about reducing the difference between predicted mapping and actual mapping of the data it is being TRAINED on. The key is "data it's being trained on". If training data is generalized enough and network is suited to learn those generalized patterns, network will perform well on validation and testing datasets too, as we observe in our very first run of model on correctly labelled MNIST data. However, even if you provide the network with incorrect or randomly labelled data, given enough size and epochs to train, a neural network will achieve good accuracy on that dataset too. However due to lack of structure in the training data, the mapping network learns would not be useful on validation and training datasets!